
Me, considering new features
Every product manager and every designer has been there.
You’ve slogged through the product research trenches for what feels like weeks. You interviewed users. You crafted personas. You made experience maps. Sharpie covers your hands and post-its litter your desk.
But despite how tired you are, the work was worth it. You found a gem. You have a brand new feature idea and all signs point to it being brilliant. You savor a moment to bask in the warm glow of your razor sharp insight and Jobsian cleverness. Time for a big reveal with your engineering team!
A few moments into your pitch they meet your gaze.
The lights dim.
Colors drain out of the world.
Time seems to slow as they begin to speak…
“Our data model won’t support that.”
“What does that even mean?!”
“Data model” and “schema” are fancy ways to say ‘how an application organizes its information.’ Organizing information sounds simple. But schema issues can be hopelessly frustrating when you don’t understand what they are. It’s natural to be resentful when idea after idea dies because ‘the schema won’t support it.’
It seems like having a functional data model should be the minimum bar for an engineering team. How hard can it be to keep the data tidy after all?
As it turns out, surprisingly hard.
Even the best decisions can lead teams down dead-end paths. Here’s a simple example of how data models evolve.
JSON
Before we start, lets take a moment to review how JSON works. If you’re already familiar with JSON feel free to skip ahead.
JSON stands for Javascript Object Notation. It’s a very common way to store and send information when building software. If you’ve heard of an API, it (most likely) uses the JSON format to transfer data.
JSON has a few simple building blocks.
The most basic of these is the key, value pair.
Key Value Pairs
Keys are a label. Values are whatever the label refers to. For example, in a phone book, a person’s name is the key and their phone number is the value. (You could do it in reverse but that phone book would be much harder to use!)
JSON writes key value pairs like this (using a few different types of values):
{
"key": "value",
"age": 15,
"gpa": 3.6,
"likes_cookes": true
}Key, Value pair examples
Arrays
Arrays are how JSON stores lists. They have a series of items listed in a specific order. To make an array, separate each item with a , and wrap the whole list in []s.
Here are some examples of arrays:
["John", "Paul", "George", "Ringo"],
[1, 2, 3],
[false],
["seven", 8, 9.0, true]Array examples
Objects
Objects can be a little tricky to understand. It’s helpful to remember that JSON stands for Javascript Object Notation. Every example above is an example of an object.
Like arrays, objects are lists of stuff. Unlike arrays, they aren’t stored in any particular order. One tricky part about objects (and arrays for that matter) is that they can be nested inside of each other.
Here’s an example of a nested object:
{
"name": "Michael",
"social_media": {
"twitter": "@mvwi",
"medium": "medium.com/mvwi"
},
"shares_encouraged": true
}The Value for the social media Key is an Object
Putting it Together
You can combine the bits and blocks of JSON together in practically endless ways. There are a few extra complexities and caveats when using JSON in the wild but for our purposes, that’s plenty of baseline knowledge.
How Data Models Evolve
Here’s a simple example of how data models can get off track.
Suppose you’re in charge of building the world’s best family tree tracking software. Let’s call it Familyizer™️. Your goal is to build a way to let people visualize their nuclear family connections. To do that, you’ll need to design a database to hold that information.
Here’s a happy family to use for this example.
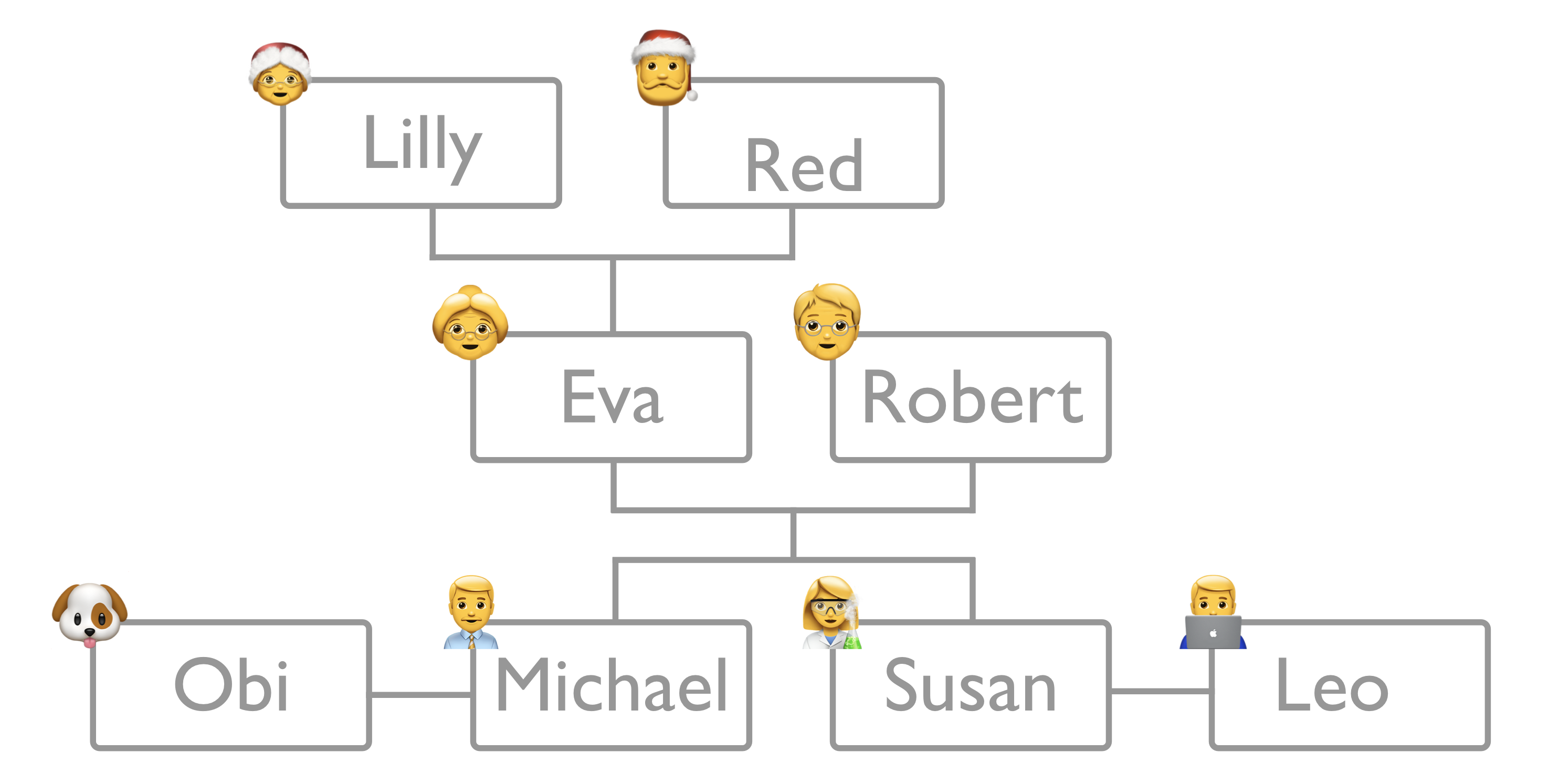
Our happy emoji family (Yes, that’s Santa. Go with it.)
If you use that family as a starting point you may come up with a data structure that looks something like this.
{
"user": "Michael Williams",
"dog": "Obi",
"mother": "Eva",
"father": "Robert",
"sister": "Susan"
}Familyizer Data Model — v0.1
Great! That looks like all the information we would need to visualize that nuclear family’s connections. But, if we generalize this structure for different families, limitations appear.
What if a user had a brother instead of a sister? What if a user had two sisters? Three? *Maybe it would be best to switch it to an array of siblings instead of individual key value pairs for each sibling.
For similar reasons, we should probably nest mother and father into an array for parents and move dog into an array for pets.
Having all of these in arrays helps us handle extra use cases like stepparents, more siblings, and new pets much more easily.
{
"name": "Michael Williams",
"pets": ["Obi"],
"parents": ["Eva", "Robert"],
"siblings": ["Susan"]
}Sample Familyizer Data Model — v0.2
That’s looking better but in removing the original sister/mother/father/dog keys we lost some information. For example, how can we tell which parent is which?
To give us somewhere to keep that extra metadata let’s use nested objects.
While we’re at it, let’s combine parents and siblings into one field called family to keep things a little more organized.
{
"name": "Michael Williams",
"pets":
[
{
"name": "Obi",
"species": "dog"
}
],
"family":
[
{
"name": "Eva",
"relationship": "mother"
},
{
"name": "Robert",
"relationship": "father"
},
{
"name": "Susan",
"relationship": "sister"
}
]
}Sample Familyizer Data Model — v0.3
Looking good! If we’re feeling really ambitious we can think ahead to supporting grandparents and siblings in law too.
{"name": "Leo", "relationship": "brother in law"}{"name": "Red", "relationship": "maternal grandfather"}{"name": "Lily", "relationship": "maternal grandmother"}
{
"name": "Michael Williams",
"pets":
[
{
"name": "Obi",
"species": "dog"
}
],
"family":
[
{
"name": "Eva",
"relationship": "mother"
},
{
"name": "Robert",
"relationship": "father"
},
{
"name": "Susan",
"relationship": "sister"
},
{
"name": "Leo",
"relationship": "brother in law"
},
{
"name": "Red",
"relationship": "maternal grandfather"
},
{
"name": "Lily",
"relationship": "maternal grandmother"
}
]
}🎉Sample Familyizer Data Model — v1.0 🎉
Fantastic! As we press the button to deploy our software life is good at Familyizer™️ HQ.
After six months of wildly successful hockey-stick growth 📈 we decide to add a brand new social feature to our product. We want to give different Familyizer™️ users a way to link their family maps together. Once everyone does, we’ll have a family tree for the whole world!
Crowdsourcing! Network effects!
You think it’s going to be fantastic and your preliminary tests say the same.
You take it to your development team. They take one look at the idea and tell you the schema won’t support it.
“What?! Again?!”
How is that possible when we designed it so carefully?
Up to this point, we optimized our schema for one person’s perspective — our user. And for that use case we did a great job. From an individual’s perspective, it’s super easy to show how they’re related to anyone. But our data model has no idea how each of the non-users relate to each other. The way we stored the data makes some comparisons impossible.
How would your application know whether your sister and your brother in law are are married? What if you had two sisters and he is married to the other one? No one wants to deal with that conversation over Thanksgiving.
Despite our best efforts, we’re stuck. The only way forward is loads of user driven manual data entry.
Not a great user experience.
How to Work within Data Model Constraints
This is a trivial example. Any competent engineer would have seen the linking problem coming a mile off and designed the schema accordingly.
But even so, it’s a good sample of how data schemas evolve. Early, reasonable decisions can become huge roadblocks as you grow.
There’s no way to build software without constraints. At some point you’re going to run headfirst into those constraints and it’s going to be frustrating and painful to get around them. Still, there are things you can do to keep that pain to a minimum.
Keep Data Models from Ruining Your Day
- Include engineers in your research and discovery efforts. The more they know, the better their choices will be.
- Share your ideas with your team early and often. Waiting to share ideas until they’re “ready” cripples your team’s ability to think and plan ahead.
- Talk about the implications of constraints you’re adding into the system. Your team will make better-informed decisions and will see roadblocks before they form.
The products you build will still have constraints. It’s impossible to build software without them. But with foresight, you can be judicious about which constraints you reject and which you embrace.