
My last prioritization meeting
Prioritizing product ideas is hard.
Prioritizing product ideas rife with interconnections and dependencies is even harder.
But despite the difficulty, it’s a critical part of any product manager’s job. Keeping a well-organized set of priorities is arguably the highest leverage thing a product manager can do.
To make this process more manageable I usually recommend splitting the process into two distinct steps: ranking and sequencing.
Ranking answers: “All constraints aside, what’s the most valuable thing we could work on?”
Sequencing answers: “Given our priorities and our constraints, what’s the most efficient thing we can work on next?”
Separating prioritization into ranking and sequencing disassociates the thinking part of the problem (ranking) from the mechanistic part of the problem (sequencing). There’s no silver bullet for the first half — deciding what’s most important is always tough. But luckily for us, sequencing is a predictable process that follows a consistent set of rules.
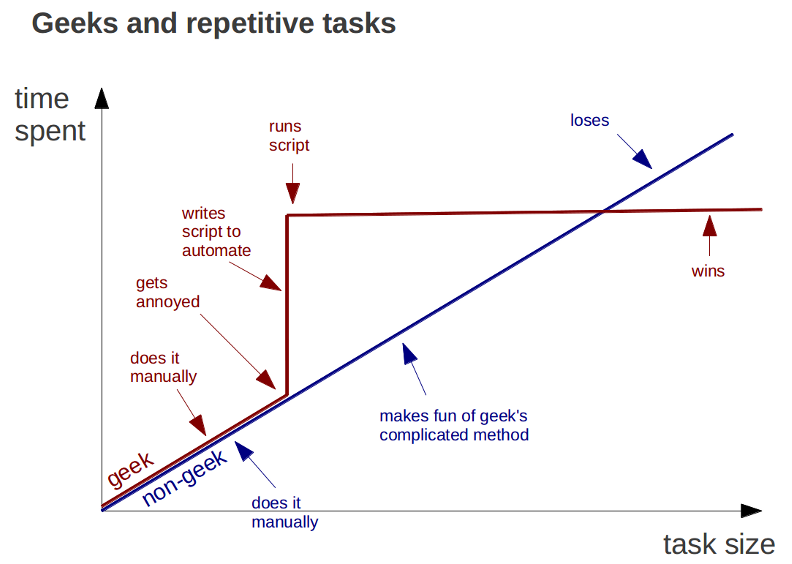
Manually following those steps is fine if you only have to do it a few times. But when priorities change around often and/or new dependencies emerge, recalculating the optimal feature order over and over again can quickly become a pain.
After far too much time manually sequencing and resequencing feature lists, I decided to automate the process with a simple python script.
This is your brain, this is your brain on Python
How it works
The script starts by reading a CSV file. That file lists features, their relative priorities, and any dependencies between them. Here’s an example input CSV.
A sample input CSV
After loading in the data, the script starts going through the list of features and sorting them based on a set of rules. Generally speaking, the script picks high-priority, low-dependency features first and low-priority, high-dependency features last. Here’s a flowchart describing the exact feature picking logic in more detail.
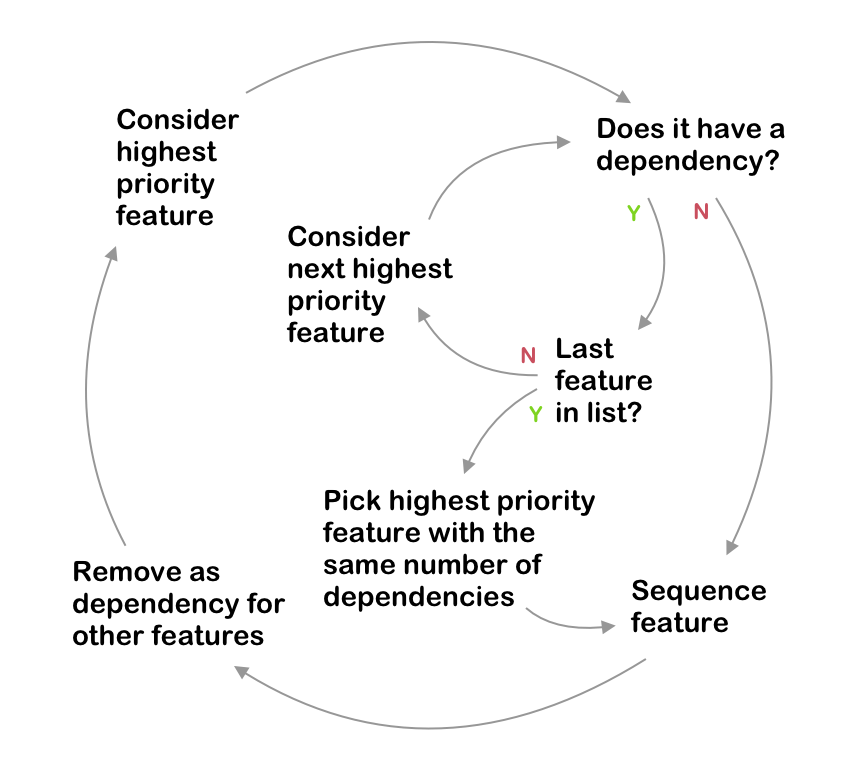
The script’s sequencing logic
To make the flowchart a little more grokable for visual learners like myself, I made a step by step illustration of the process as it sorts the features in the sample CSV above. The highlights show where the script is focused and what action the script is taking. Blue and red subscripts show open and resolved dependencies respectively.
The sequencing algorithm in action
After the script finishes, it prints the results to a table like this.
You’ll notice two new columns. sorted_priority is the optimal order to work on these features given their priorities and dependencies. priority_change tracks how much the order of the features changed.
Running the script
Prerequisites:
- A working Python 3 installation
- The
numpyandpandaspackages installed - A basic understanding of how to navigate around your computer using the command line
If any of these bullets are Greek to you then you have two choices. Option one is stopping here and using the above approach and flowchart next time you have to prioritize work. That’s a perfectly reasonable decision and I wouldn’t fault you for taking it.
Option two (the one I hope you’ll take), is spending an hour or two learning about Python and the command line. Regardless of your role, having even basic technical chops will pay big dividends in the long run. A quick Google search will turn up loads of learning resources. It looks like Django Girls has a good primer but there are plenty of others. Feel free to pick one that matches your learning style.
Now that the base knowledge is out of the way, here’s how to run the script:
- Save the code below to a file with a name that makes sense to you (I chose
prioritize.py). - Using the input CSV format above, create a CSV in the same folder as the python script (I called mine
source_features.csv). In that CSV, list out the features, priorities, and dependencies that you would like to sequence. - Open your terminal and use
cdto navigate to the folder where you put the python script and the input CSV. - Run the script using
python3 YOUR_SCRIPT_FILENAME --source YOUR_INPUT_CSV_FILENAME - Enjoy!
By default, the script prints the results back into the command line. If you’d like to print the output to another CSV file instead, add the --output flag and a destination filename to the command (e.g.: python prioritize.py --source source_features.csv --output sequenced_features.csv)
Happy prioritizing!
The script
import pandas as pd
import numpy as np
import argparse
# Set up the command line parser
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--input", help="Source file", required=True)
parser.add_argument("-o", "--output", help="Destination file",
required=False)
args = parser.parse_args()
def load_feature_list(filename):
df = pd.read_csv(filename)
df['sorted_priority'] = np.nan
df['dependency_count'] = np.nan
# Turn the string of dependencies into a list
df['temp_dependencies'] = df['dependencies']
df['temp_dependencies'] = df['temp_dependencies'].apply(_split_dependencies)
return df
def process_feature_list(df):
while len(df) > df['sorted_priority'].count():
# Sort rows by the number of dependencies each row has
df['dependency_count'] = df['temp_dependencies'].apply(len)
df.sort_values(by=['sorted_priority', 'dependency_count',
'priority'], inplace=True, na_position='first')
df.reset_index(drop=True, inplace=True)
# Assign whatever priority is next to the item with the
# fewest dependencies and highest priority
df.at[0, 'sorted_priority'] = _next_priority(df, 'sorted_priority')
# Remove that now 'completed' item from the list of dependencies
# for other features
df = _pop_dependencies(df, 'temp_dependencies', df.id[0])
return df
def print_feature_list(df):
# Calculate how priorities have changed based on the dependencies
df['priority_change'] = np.nan
df['priority_change'] = df['priority'] - df['sorted_priority']
# Sort one last time for a pretty print
df.sort_values(by=['sorted_priority', 'dependency_count',
'priority'], inplace=True, na_position='first')
# Extract the columns we actually care about
pretty_df = df[['id', 'name', 'sorted_priority',
'priority', 'dependencies', 'priority_change']]
print(pretty_df)
if args.output:
pretty_df.to_csv(args.output, index=False)
def _split_dependencies(x):
if pd.isnull(x):
return []
if type(x) is str:
return x.strip().split(',')
def _next_priority(df, col):
# returns the next
if pd.isnull(df[col].max()):
return 1
else:
return df[col].max() + 1
def _pop_dependencies(df, column, item):
for x in range(len(df)):
df.at[x, column] = [x for x in df.at[x, column] if x is not item]
return df
# --------------- MAIN ---------------
df = load_feature_list(args.input)
df = process_feature_list(df)
print_feature_list(df)Note: This is a simplified model! It won’t account for some intracicies like differing development times and parallelizing work. If the output doesn’t quite jibe with what you know is possible then tweak it! As always, do what makes sense for you.
If you’d like a hand thinking through your situation, comment below or send me a note on twitter.