
Managing technology projects and teams is full of hard decisions and imperfect information.
Should you prioritize speed or quality?
Should you fix tech debt or focus on new features?
Should you build or buy?
These decisions are rarely straightforward and are never easy. A decision made in one place can have big unexpected consequences somewhere else. Navigating between alternatives is a balancing act that is hard for even the most experienced among us to pull off. But making those choices — and more importantly, communicating them — is essential.
Generally, people rely on gut, intuition, or even worse, Best Practices™️, to help them make and justify their decisions. But those approaches are all half measures at best. They try to answer What We Should Do but they totally neglect Why Should We Do It.
Talking about alternativesis easy — everyone can stumble through a debate on meeting cadences and test coverage. Talking about the reasoning behind the decisions and the consequences of them (the Why Should We Do It) is much, much harder.
Referencing Best Practices™️ is a cheap shortcut.
But taking that “because I told you so” approach shuts out the people who need to understand the decisions the most. It can make decisions feel arbitrary and the teams who make them seem uncooperative and adversarial.
But some companies don’t tolerate “because I told you so” cop-outs. Instead, they push their teams to understand each other. When that happens, trust, transparency, and collaboration across functional areas increases and everything just seems to work.
The communication gap between technical and nontechnical teams is big and getting bigger. It’s a huge emotional and productivity drain on everyone involved. Fixing that problem will do more for the health of our teams, organizations, and products than any number of Agile seminars, corporate mixers, or design thinking workshops ever will.
I’ve tried bridging the communication gap in a lot of ways. Some have worked well, others less well. My favorite approach so far comes from the field of system dynamics.
System Dynamics
Jay Forrester, a professor at MIT, developed the field of System Dynamics in the 1950s. Trained as an electrical engineer but working in the newly formed Sloan School of Management; Forrester started experimenting with ways to apply scientific techniques to problems in business.
As a venue for his research, Forrester worked with a handful of large companies. His goal was to solve seemingly intractable business problems. Not only did he succeed and help the companies he was working with, but he developed a new way to understand complex systems in the process. This approach is now called System Dynamics.
Forrester showed that, contrary to popular opinion, most of the problems that the companies were facing weren’t caused by external factors like competition or poor economic conditions.
Instead, they were created by causes and effects, feedback loops, incentives, and relationships within the companies themselves. By helping managers understand the internal structure of their companies, Forrester revealed how well-intentioned policies were actually causing problems they were trying to avoid. With that new knowledge, the managers changed their approach and fixed the problems for good.
How It Works
System Dynamics brings together two principles which, when combined, make complex systems like the inner workings of a business much easier to understand.
The first principle doesn’t need much explanation — visually representing data makes it easier to absorb. Graphs are better than tables.
The second principle comes from Forrester’s background in the sciences. In fields like engineering, real-world experiments can be expensive, difficult, and time-consuming to run. In those cases, simulating an experiment mathematically is a cheap and fast way to learn. Simulations take static models and give them immediacy and life.
Forrester’s insight was how well these two principles reinforce and amplify each other. Joining together visual representations of complex systems and the ability to model them mathematically lets you see how the system evolves over time. You can discover where the leverage points are within the system. And you can experiment with different approaches to changing how the system behaves.
For complex systems full of feedback loops (such as businesses and technology), System Dynamics is an amazing tool.
Modeling Software Systems
The model used in the rest of this article will be very familiar for anyone working in software development. It explores how code quality, refactoring policies, and waste impacts the amount of code a team can ship and maintain.
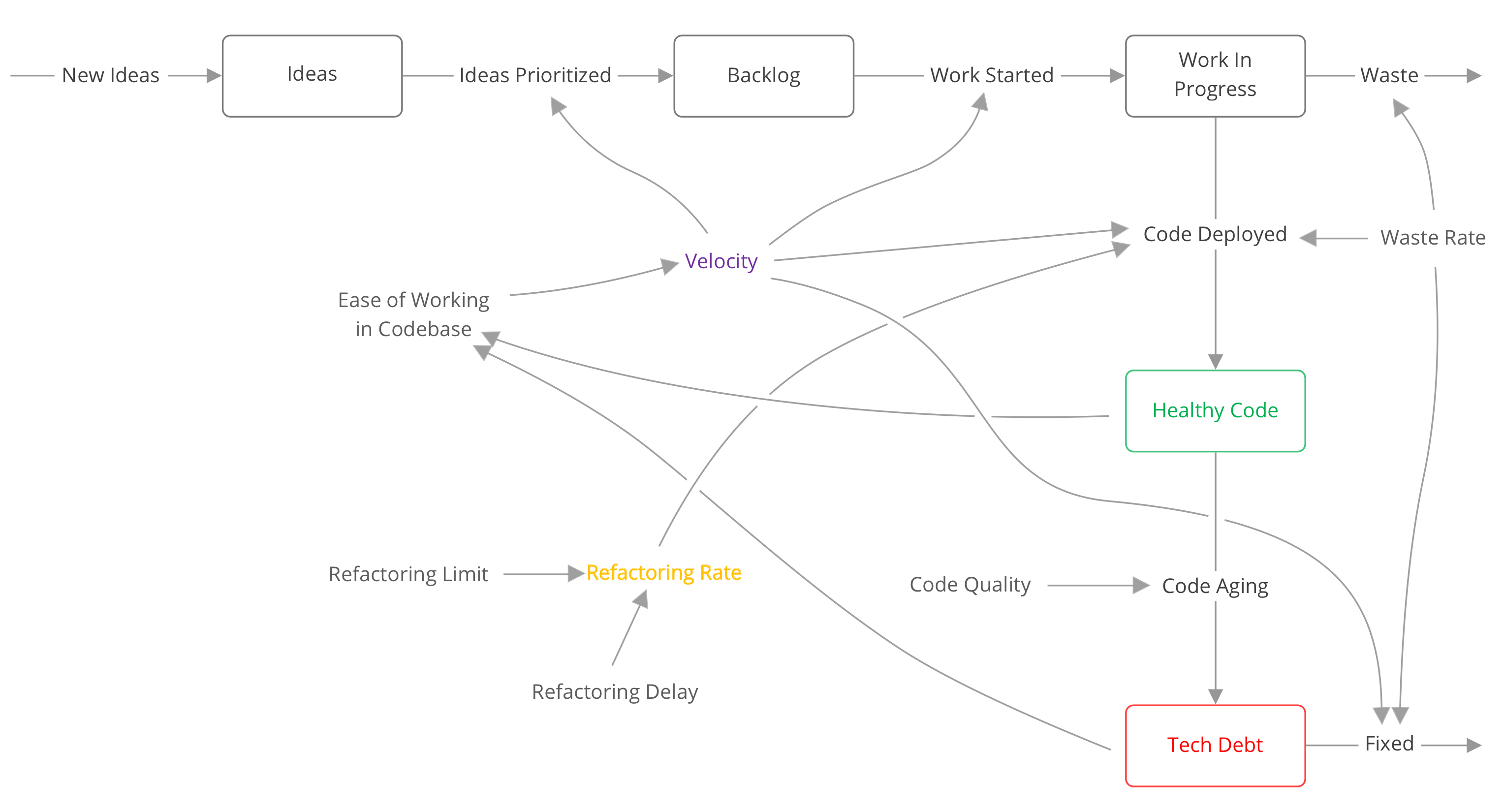
Remember, every model is wrong but some are useful. I’m sure some of you will find issues with this simplification. But for our purposes right now, it’s a good balance of accuracy, complexity, and understandability. To learn more about reading models click here.
Despite how central these tradeoffs are to software development, they can be very hard to understand — especially for people who haven’t experienced them first hand. System Dynamics gives us a way to represent those tradeoffs visually and quantitatively.
To start, consider the dynamics within a healthy team.
Healthy Team
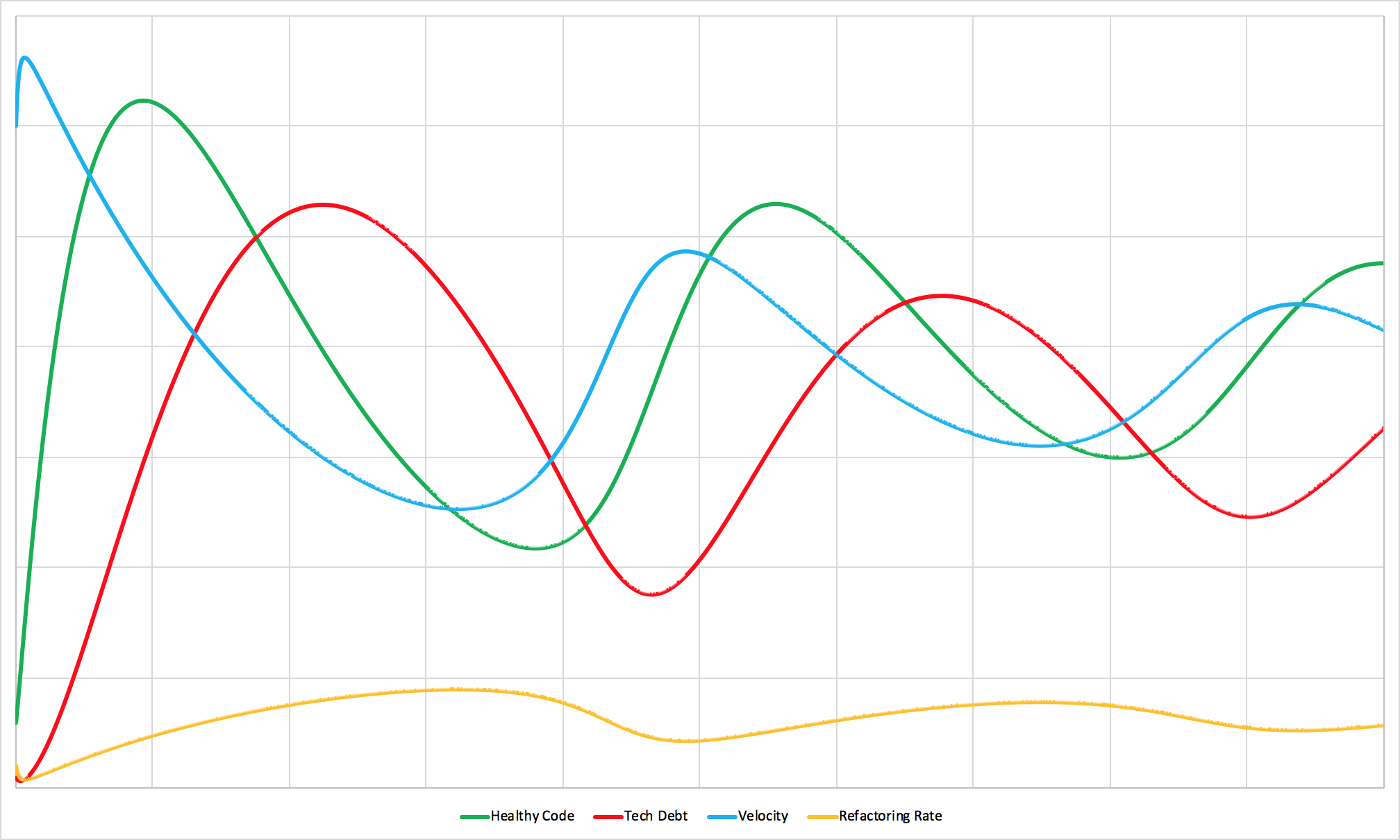
A healthy team with a good balance of speed, quality, and flexibility.
In this simulation, we have a team who starts off with some small level of working software and very little tech debt. Because they have such a small amount of debt to deal with, their environment is very easy to work in and they’re able to release a lot of new features quickly. The amount of healthy, working code they have grows dramatically!
As they ship new features, the team discovers that some of their early ideas or implementations weren’t ideal. Those well-intentioned but slightly incorrect ideas are now constraints they have to work around. In other words, some of the once-healthy code they shipped starts to become tech debt.
As the ratio of tech debt to healthy code increases, the team’s velocity slows. Because this is a good team with quick feedback loops, they recognize the slowdown and allocate more of their time to fixing issues.
It takes a little while for the team to address the debt that has accrued (especially since healthy code continues to age while they’re working) but before too long they’ve made good progress. The codebase is easier to work in, velocity increases, and the team has more time to spend on new features. They release the next wave of features, debt grows, and the system starts the cycle again.
In practice, outside shocks (new technologies, new market opportunities, regulation changes, etc.) can cause big swings in the system. But, if left to their own devices, this is the natural rhythm that healthy teams find.
Sometimes they can release a bunch of new features. Other times they need to slow down, reassess, and redo.
This dynamic emerges when teams have healthy development practices like high code quality, low priority thrash, and the ability to decide the right balance of new features and refactoring. When any of those inputs change, the output and efficiency of the system will change too.
Low Code Quality
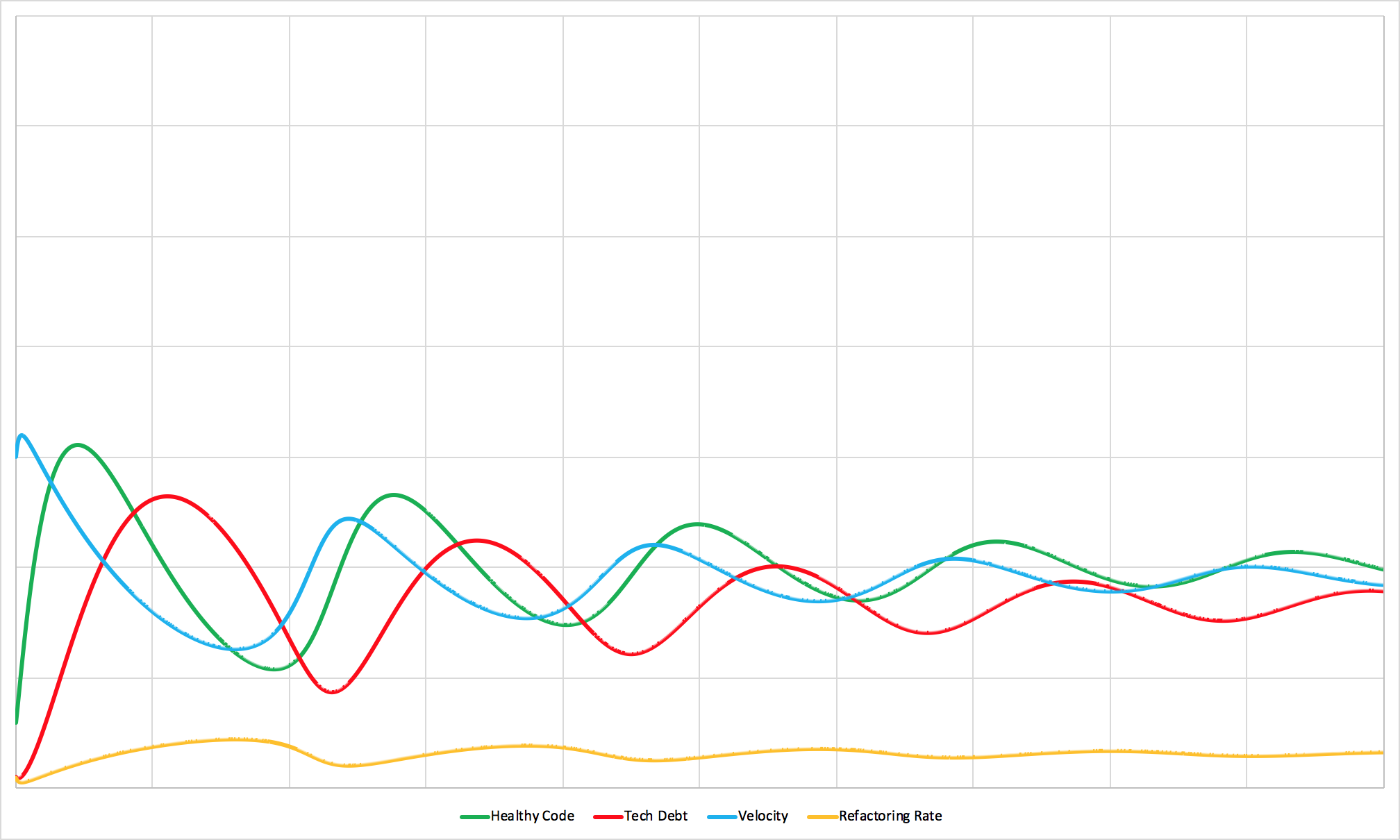
An otherwise healthy team producing low-quality code.
Code quality is a big determinant of how fast healthy code becomes tech debt. Lower quality code ages faster than higher quality code does.
If you compare this simulation against the Healthy Team simulation you’ll notice two things.
The first is that the frequency of the cycles is much faster. That makes sense. If code quality is lower, healthy code will become tech debt at a faster rate. The ratio of tech debt to healthy code grows much faster and the team has to stop to address debt more often.
That constant switching leads to the second impact. Between healthy code aging into tech debt faster and the constant switching between new work and refactoring, the team can’t maintain as big of a product. The average level of healthy code over time is much lower than it is in the first simulation.
If you extrapolate that out to the company-wide level, that means that organizations with low-quality code need more development teams to support a smaller number of features.
For organizations who have large tech teams but struggle to ship new features, code quality standards may be a high-leverage place to intervene.
Changing Priorities
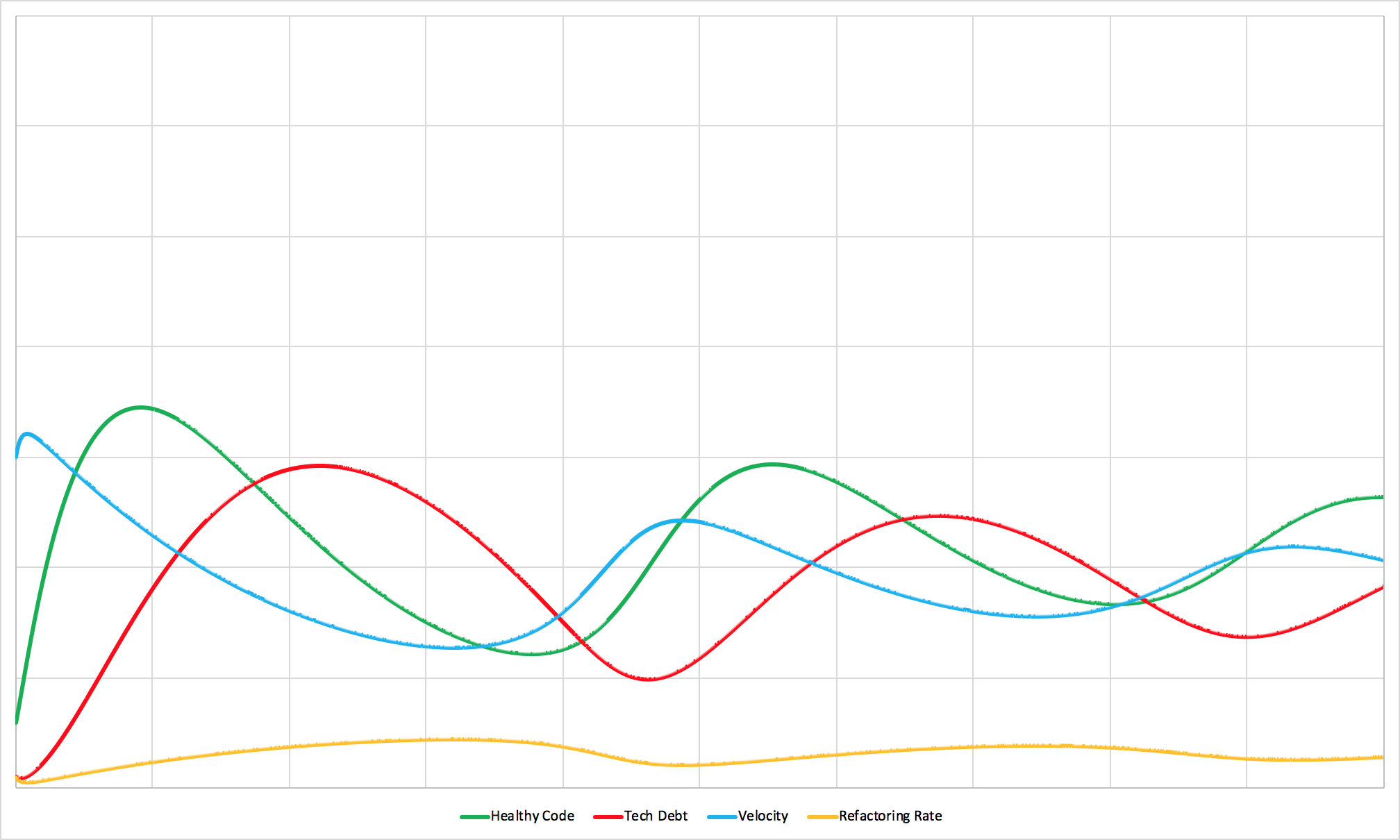
A healthy team with a high degree of wasted work.
Building software takes time. And as it’s being built, priorities often shift. When that happens, work that was in progress may need to be thrown out, shelved for later, or redone.
Changing priorities is a natural part of the software development process. But it can cause problems depending on how often it occurs. If priorities change too often then it leads to thrash and a lot of short-term wasted work. If priorities don’t change quickly enough then the team can spend a long time working on low value (or in some cases harmful) projects. There are few things more demoralizing than spending a year or two working on a feature that gets canned before it’s released.
*Tangentially, this is exactly why Agile methods work. They keep the amount of work in progress low by working in small pieces and releasing as often as possible. That way when priorities change (which they should with new information), the team can toss out small pieces of work instead of big ones.
Priorities shifting too often and priorities not shifting often enough both manifest the same way. They both turn some part of the team’s work into waste.
Waste doesn’t impact the amount of work a team does, but it does impact what percentage of that work makes it into production. That inefficiency impacts both work for new features and work that addresses tech debt.
A high degree of waste doesn’t change the dynamics of a team as dramatically as some of the other issues that can crop up. The shape and frequency of the team’s development cycles are largely unchanged. The difference is in the amplitude — the amount of work that the team is able to ship.
A five-person team with 40% waste might as well be a three-person team. And no matter how well organized the rest of the team is, three people simply can’t produce or maintain as much as five people.
How often priorities should change depends on the team, product, and organization.
Startups still searching for product-market fit will have a much higher rate of change than infrastructure teams at huge corporations. That’s normal. But if you find yourself constantly throwing away work or working on things that you know aren’t the most valuable options, that’s a good signal that it’s time to reconsider how and when you shift priorities.
Refactoring Delays
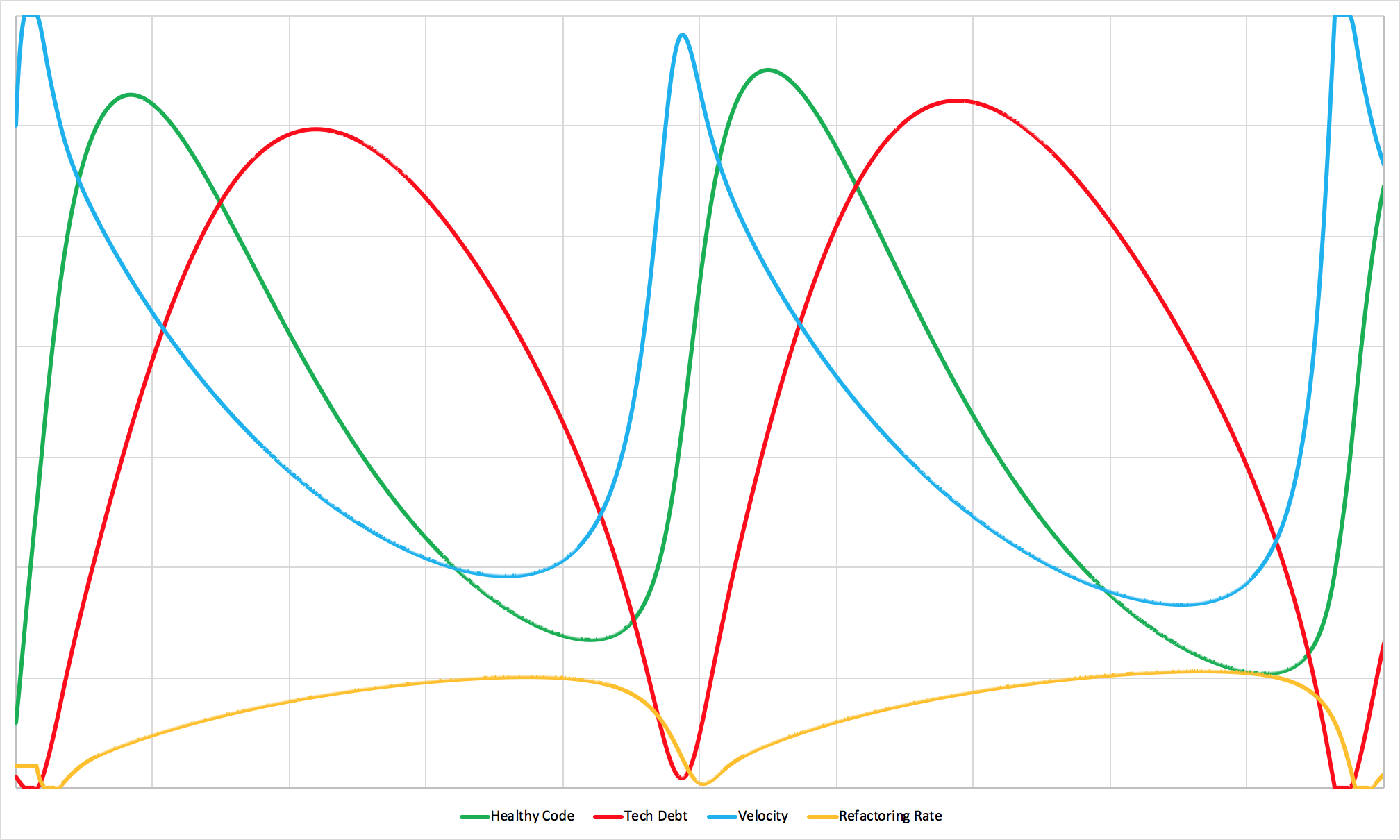
A delay between the ease of working in a codebase changing and a team’s ability to change focus.
Delays in a system’s feedback loops make it harder for the system to make rational decisions. They often cause over or under-reaction to changes and tend to cause big oscillations. Delays are one of the biggest causes of unpredictable behavior in systems.
Up until now, the model has included a large (and questionable) assumption. It has assumed that the team can adjust the amount of time it spends refactoring in real time.
That assumption is a nice abstraction that makes the system easier to model and understand but it doesn’t hold up to reality. There is almost always a delay between a codebase starting to feel bad and when the team starts work on the underlying issues. The longer that delay stretches, the wilder the swings in the system are.
In the simulation above, adding a relatively small delay introduces big swings between over investment and underinvestment in addressing tech debt. At times, new features are shipped as fast as possible without any regard to the later consequences. At other times tech debt is attacked with maniacal focus. The team’s velocity swings erratically and predicting the team’s output becomes practically impossible. If you increase the delay more, the swings are even more frantic.
Asking teams to adjust their refactoring rate minute by minute may not be realistic. But if there is a large delay (for example, a few sprints worth of committed work) that inhibits teams from making quick adjustments then it could be the source of a lot of inconsistency. Counterintuitively, giving teams the authority to pull the cord and address debt may actually make the system more predictable.
Refactoring Limits
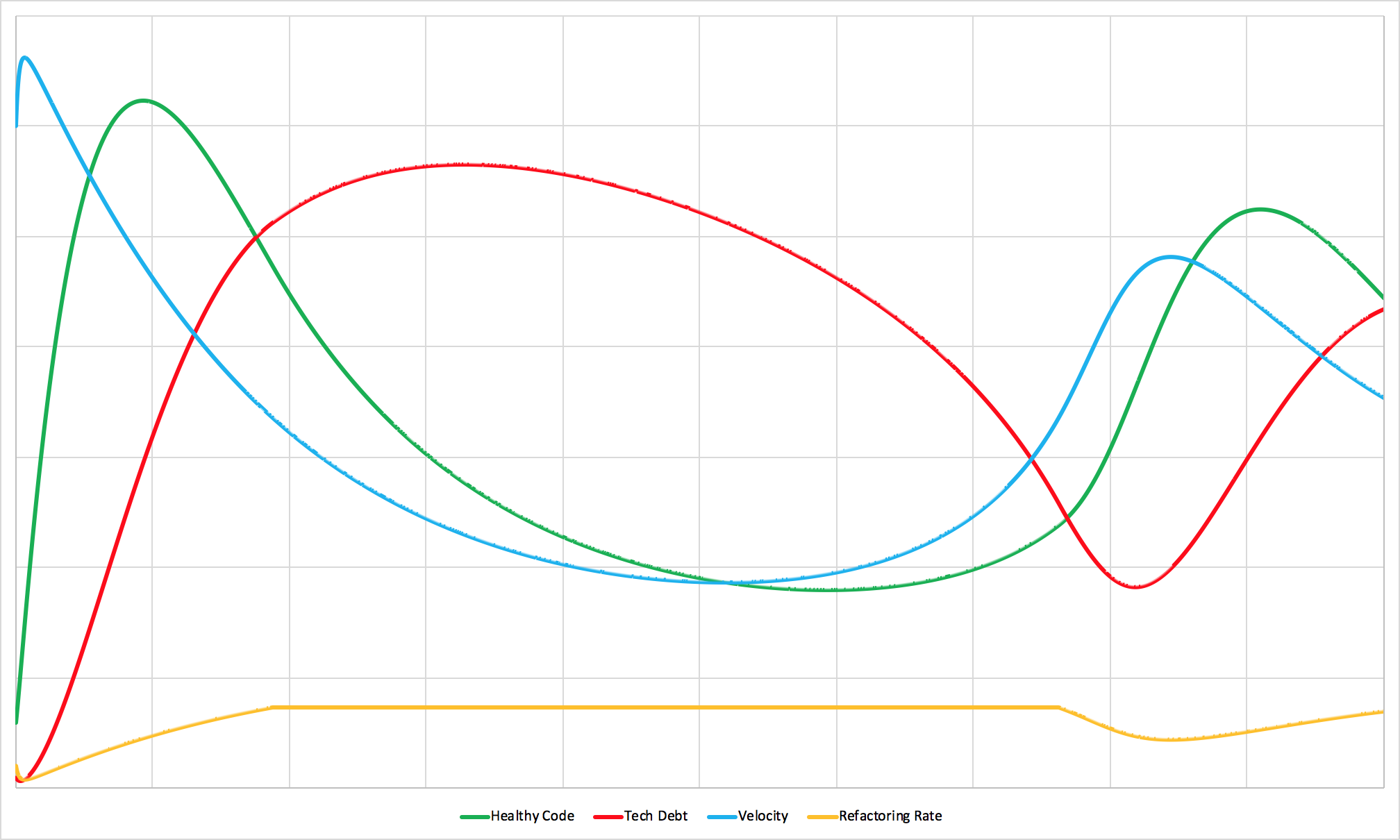
A team with a cap on the amount of time they can spend refactoring.
Many teams have a limited amount of time they’re allowed to work on paying down technical debt. Rules like “Spend at least 70% of your time working on new features” are very common. For executives, marketing departments, salespeople, and others whose livelihoods depend on press releases this can be a very seductive and seemingly logical rule. But, keeping a team focused on new feature development can have surprising long-term negative consequences.
When working with complex systems, people often immediately recognize a leverage point but have the exact wrong intuition about which direction to push it.
This simulation imposes a very weak restriction on refactoring time. It only comes into play when the amount of tech debt has become very large.
Instead of taking the short-term hit to new feature development and getting the tech debt out of the way, the team continues to spend a large chunk of their time working on new features. As new features are released and the tech debt isn’t paid down the team’s velocity falls. With lower velocity, it takes longer to ship both new features and fixes to the tech debt. The team limps along, working in an unforgiving environment while slowly chipping away at the mountain of tech debt. After a huge amount of time they finally make enough headway that velocity starts to increase. They shift focus back to new development. Their relief is palpable but short-lived — as soon as they speed up new feature development the cycle starts again.
The average level of healthy code in the simulation above is much lower than in the Healthy Team simulation. Counterintuitively, reserving time for new feature development actually reduces the amount of healthy code in the product. Instead, it extends the amount of time the team has to spend at the mercy of the tech debt they’ve accrued.
The simulation above uses a very weak refactoring rate cap. If you restrict refactoring even more then the system quickly degrades to the point that it’s totally out of control.
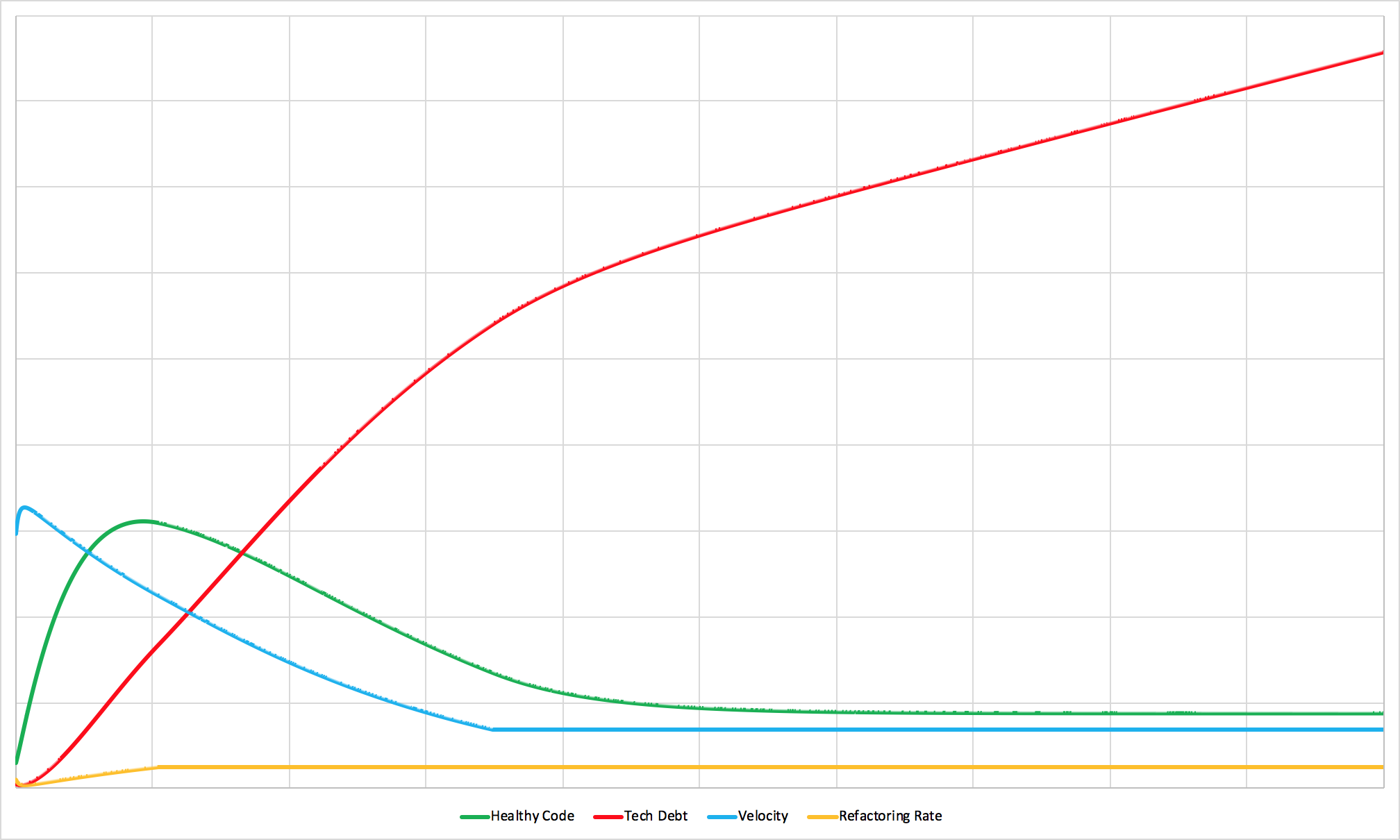
A team with (surprisingly not that heavily) constrained refactoring time.
In this simulation, tech debt grows faster than the team can pay it down. New feature development drops to a crawl. And if not for the floor on velocity (hiring new team members as the fed up ones quit), the team’s output would drop to zero.
This is the organizational equivalent of overfishing to the point of environmental collapse. Clearly not the policy’s original goal.
To dip back into our store of well-worn maxims, sometimes you just have to bite the bullet or suffer the consequences.
These scenarios are based on a very simplified model of how software teams work. This model only has a few variables and the scenarios above only show one variable changing at a time.
The real world isn’t so simple. It has outside shocks like new economic conditions or regulatory changes. It interacts with parallel systems like HR, finance, and legal. Removing those convenient constraints can make incredibly complex relationships emerge.
Still, the core dynamics of software teams remain the same no matter how convoluted the systems surrounding them become. Healthy teams still swing between releasing new features and addressing debt. Delays can be beneficial or problematic depending on how they occur. Refactoring is (usually) a good long-term use of time.
Navigating the decisions that surround building software will never be easy but it doesn’t have to be as hard as we make it.
Imagine a world where technologists and business people sit down together to have rational conversations about speed versus quality. Addressing tech debt versus building new features. Building versus buying.
Imagine what those teams could accomplish.
The biggest barrier to that world isn’t motivation or desire. Most people genuinely want to understand and make reasonable requests of each other. The biggest barrier is communication. When people don’t understand the consequences of their requests or don’t understand how to communicate them there’s no way to find common ground.
We need a common language so that instead of talking past each other we can talk with each other.
System dynamics, although not a complete solution, is a good step in that direction. It helps anchor conversations in something less dogmatic than best practices and more tangible than opinion. Using system dynamics simulations as a focal point has led to some of the healthiest debates I’ve ever had.
But don’t take my word for it.
Get out there, try it out, and see what happens. It might be just what you need to take the next step forward.